ChainerX Beta Release
Today, we announce ChainerX, a fast, portable, and extensible backend of Chainer. It is aimed at reducing the host-side performance overhead as well as making models much easier to ship for applications. ChainerX is included as an optional feature of Chainer v6.0.0 beta1, and is planned to be officially released as a part of Chainer v6 series next Spring. You can find the official documentation, including a quick tutorial.
Background
Chainer was developed as a pure Python package, which enabled a simple interface for a Define-by-Run deep learning framework. It heavily depends on NumPy and CuPy, which are both implemented in fast, compiled languages (C and Cython, respectively). Most heavy deep learning tasks work best on NVIDIA GPUs, and, thanks to its asynchronous computing architecture, the framework overhead has been hidden by the sequence of heavy GPU kernel executions. This enabled a deep network system based on Chainer to take the record for the fastest training of a large convolutional networks at the time.
The situation is changing. GPUs are evolving rapidly compared to CPUs, and more and more accelerator chips optimized for deep learning computation are available. As a result, the host side operations are becoming the bottleneck of many tasks, including computer vision, automatic speech recognition, and natural language processing. Some research outcomes are being supplied to application areas, which increases the demands of deploying deep learning models for products and services in reliable and portable ways.
While pure Python is easier to work with and design, it incurs heavy host-side overhead, and dependency on CPython can be an obstacle to porting models to applications. We found that the design of the multi-dimensional array and the define-by-run automatic differentiation is mature, and radical design changes are not expected. ChainerX is designed from scratch as a C++ implementation of these mature components to solve both the performance and the portability issues.
Overview
The “X” suffix of the name stands for three keywords that represent its aim.
- Accelerated: It implements an ndarray with autograd feature in C++, removing the host-side overhead related to automatic differentiation.
- Exportable: Thanks to the C++ implementation, it opens the door to porting models onto Python-free environments. Note that ChainerX itself does not include any features to actually port the models; yet the pure C++ ndarray implementation with autograd makes it much easier to introduce such a mechanism.
- Extensible: As noted above, there are increasing demands of supporting a wider range of computing environments. The new ndarray has a modular design that enables us to plug-in a computing backend that supports new devices.
ChainerX currently covers the ndarray and automatic differentiation part of Chainer. The ndarray and the chainerx namespace follow NumPy-like APIs. The implementation is written in C++, while a thin Python binding layer is provided. We added built-in support of this new ndarray for existing Chainer APIs, including Variable, so that users can immediately start using ChainerX with only slight changes to the user code.
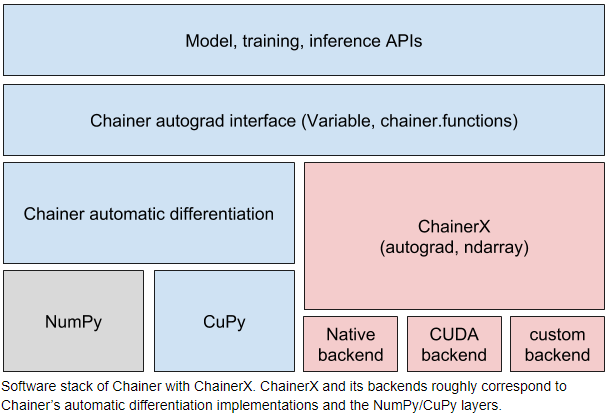
ChainerX provides the following three levels of interfaces.
- C++ API (unstable yet): The fastest interface to use if you do not need Python. Backend plugins require this layer to cooperate with.
- Python API: A thin wrapper of the C++ API. It follows the NumPy API design, so users familiar with NumPy can quickly learn this API.
- Chainer on ChainerX: The existing Chainer API also supports the new ChainerX ndarray similarly to NumPy/CuPy ndarrays. It incurs some overhead, but it is the easiest way to start using ChainerX based on existing code base.
The following is a quick comparison result of host-side overhead.
| Framework | Time per iteration (= fwd+bwd+update, msec) |
|---|---|
| Chainer on NumPy | 14.48 |
| Chainer on ChainerX | 7.54 |
| ChainerX Python | 1.88 |
| PyTorch | 2.45 |
While ChainerX lacks some operation implementations (see the limitations page for more information), Chainer on ChainerX supports automatic fallback to existing NumPy/CuPy based code for forward, backward, and update. Note that this compatibility layer also has some overhead, and we will continue exploring the best way of getting the maximum performance with small code changes.
Future
During the beta phase of Chainer v6, we will add more features to ChainerX so that it can accelerate a wider range of research and applications. We will also continue exploring other ways to adopt the fast Python API of ChainerX in more research projects.
ChainerX is just a half of the picture that covers the whole scenario of fast research and quick model shipping. The Chainer team is also working on translating the models written in Python to a portable format based on ONNX, and running the exported neural net with the ChainerX C++ implementation. We are looking forward to realizing this new research and application cycle, and seeing more and more researchers, practitioners, and engineers play with this evolving framework.
About Chainer
Chainer is a Python-based, standalone open source framework for deep learning models. Chainer provides a flexible, intuitive, and high performance means of implementing a full range of deep learning models, including state-of-the-art models such as recurrent neural networks and variational autoencoders.
Recent Posts
- Chainer/CuPy v7 release and Future of Chainer
- Chainer/CuPy v7のリリースと今後の開発体制について
- Sunsetting Python 2 Support
- Released Chainer/CuPy v6.0.0
- ChainerX Beta Release
- Released Chainer/CuPy v5.0.0
- ChainerMN on AWS with CloudFormation
- Open source deep learning framework Chainer officially supported by Amazon Web Services
Categories
- General (12)
- Announcement (10)