Performance of Distributed Deep Learning using ChainerMN
At Deep Learning Summit 2017 in San Francisco on this January, PFN announced advancements on distributed deep learning using Chainer in multi-node environment. In this post, I would like to explain the detail of the announcement.
(This post is translated from the original post written by Takuya Akiba.)
Despite the performance of GPU continuously improves, the number of parameters in neural network models and the computational cost for training them are also increasing to realize higher accuracy using larger training dataset. Some use-cases can take more than one week to train on a single GPU using frameworks including Chainer. In order to handle larger size of training dataset and to make iterative trial-and-error more efficient, it is paramount to accelerate the training process by coordinating multiple GPUs. Therefore, PFN developed a package named ChainerMN (Chainer Multi-Node), to add a distributed training functionality to Chainer.
Principle of ChainerMN implementation
The current implementation employs data-parallel computation for distributed training, especially with synchronous model update. In this approach, each worker owns a copy of the current model, and all workers calculate gradients together on a minibatch in each iteration by dividing the minibatch into subsets.
ChainerMN depends on MPI for inter-node communication, so that it can enjoy the benefit from faster network infrastructure such as InfiniBand. NVIDIA’s NCCL is then used for intra-node communication between GPUs.
Performance evaluation result
We evaluated the performance of ChainerMN on the ImageNet classification dataset using a CNN model (ResNet-50). All of the experiments ran on a computing environment provided by Sakura Internet. Please refer to the Appendix on the bottom for more details of experimental settings.
Note that the following performance results might not be completely fair, even we intended to perform as fair comparison as possible. First, the implementation of ChainerMN has been highly optimized to the experimental environment, since ChainerMN was developed on it. Second, tuning for other frameworks in the later comparison might not be sufficient, though we tried to do our best by carefully reading the official documents, tutorials, and even existing issues on Github. To encourage reproductions by third parties, we are planning to publish the experiment code also for other frameworks.
Performance of ChainerMN
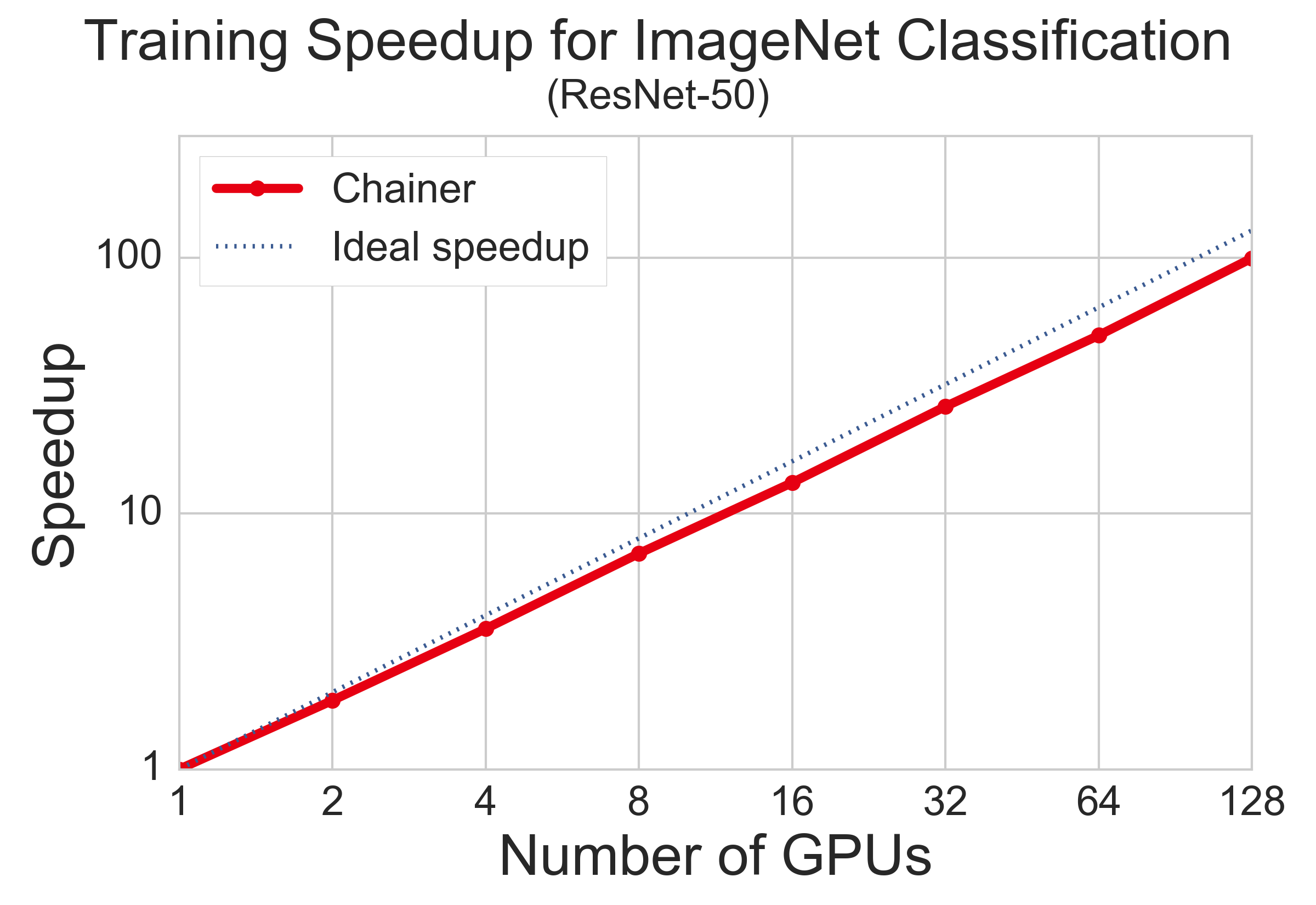
The following figure shows how much the training time is reduced when increasing the number of GPUs. Each training process ends when it reaches the same number of epochs. Up to 4 GPUs, only one node is used, but multiple nodes are needed for 8 or more GPUs. The result is fairly close to the ideal speed-ups, as the training process is accelerated for 100 times using 128 GPUs in this setting.
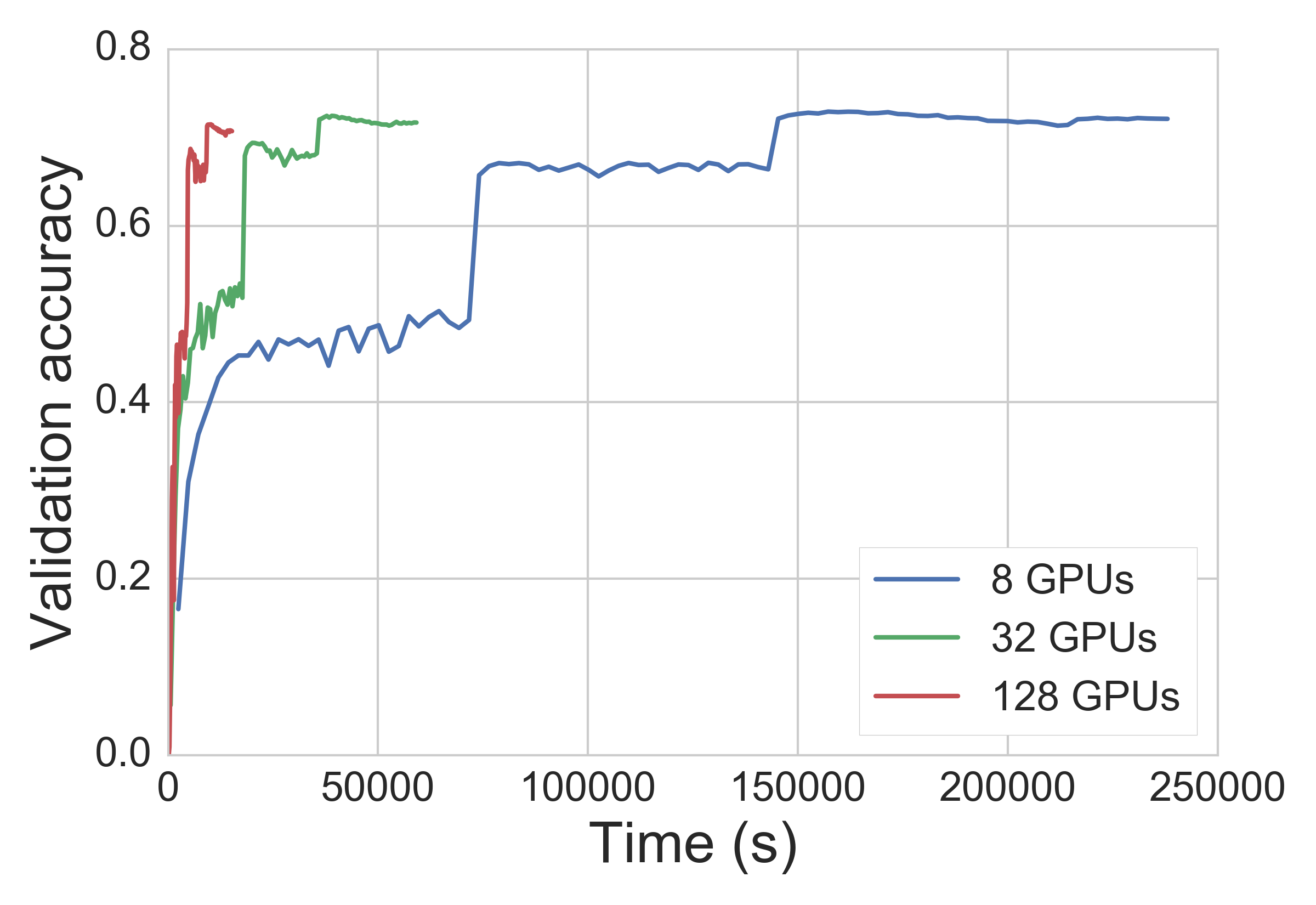
The next plot represents learning curves, as the horizontal and vertical axes represent computational time and validation accuracy, respectively. Two large bumps in the curves are caused by multiplying 0.1 to the learning rate (after each 30 epochs), which is a common heuristic in this ImageNet task.
Comparison with other frameworks
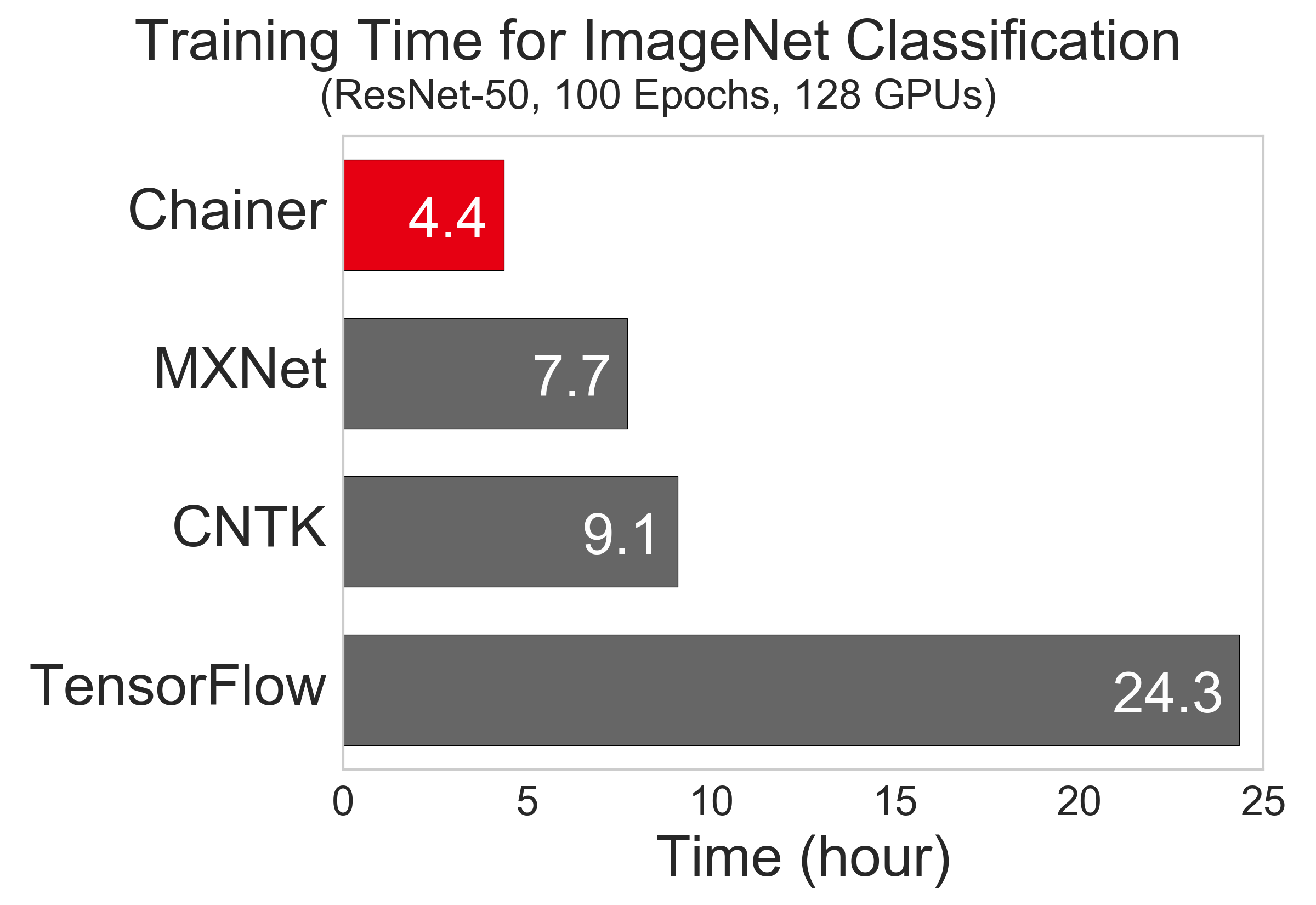
The next figure summarizes the computation time of each framework when using 128 GPUs. Surprisingly (also for PFN development team), ChainerMN is the fastest among them. We will discuss the reason of this result through other experiments in the following.
The following figure depicts throughputs of the frameworks when changing the number of GPUs. Though the measured throughputs seem a bit unstable due to small number of iterations, you can still see a trend among them. When using only 1 GPU, MXNet and CNTK are faster than ChainerMN, mainly because both frameworks are implemented in C++ unlike Chainer (Python-based). With 4 GPUs, only MXNet becomes a bit slower. This can be because CNTK and ChainerMN uses NVIDIA’s NCCL for collective communication between GPUs in each node. On the other hand, in the multiple node setting, MXNet and ChainerMN show better scalability than CNTK. As a result of faster performance in both inter/intra node communications, ChainerMN achieved the best throughput with 128 GPUs.
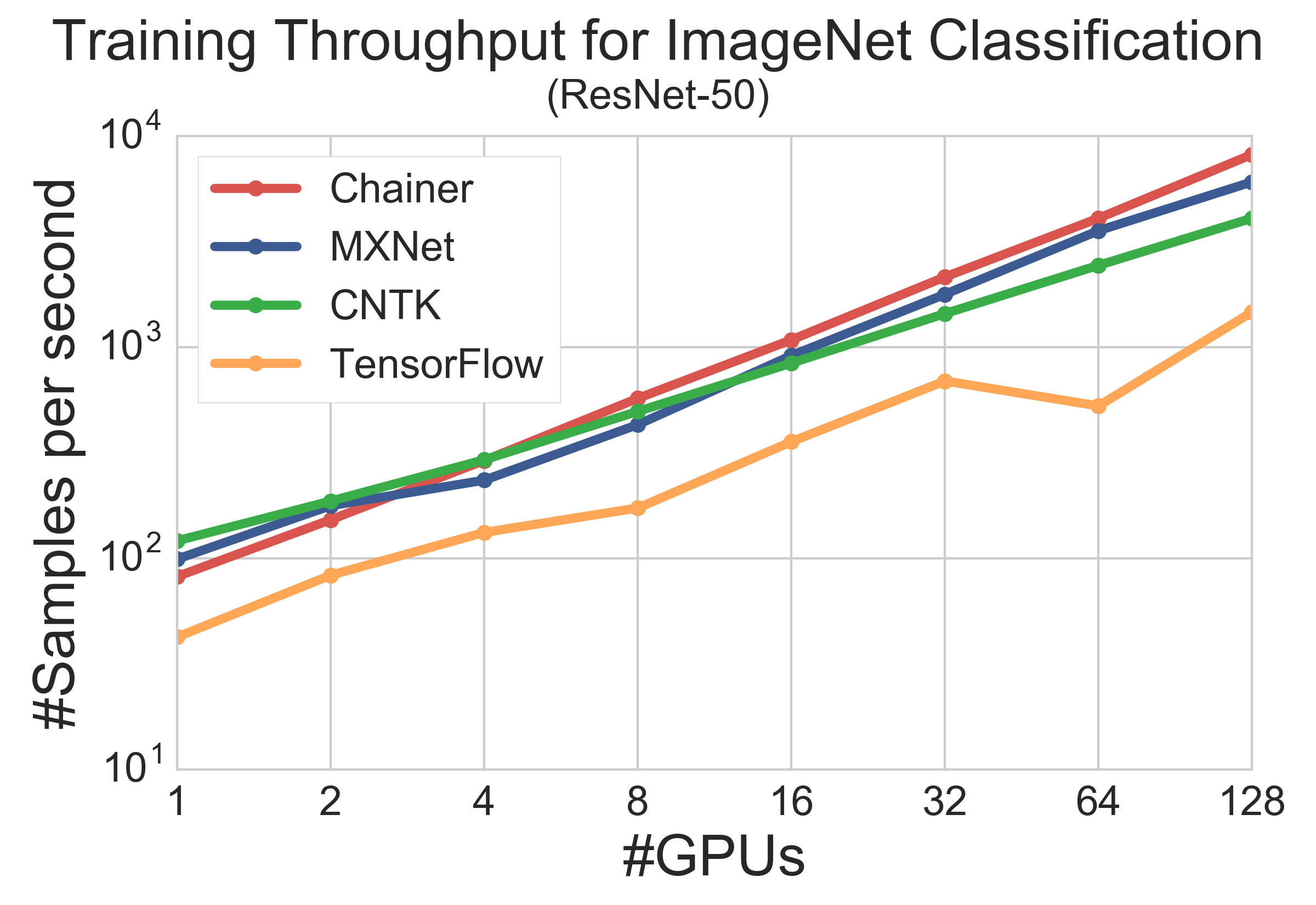
Note that we have to be careful when analyzing the results of TensorFlow, because it is a fast enough framework in standalone mode. The reason why it performed poorly even with 1 GPU is that it also runs in distributed mode as well as the other frameworks. Since there seems to exist a substantial overhead in gRPC communication between worker processes and independent parameter server, the performance of distributed TensorFlow is different from that in the standalone mode even with 1 GPU. This result also agrees with some earlier evaluations on the performance of distributed and multi-GPU TensorFlow reported by third parties, such as [1, 2].
- [1] “Benchmarking State-of-the-Art Deep Learning Software Tools”, Shaohuai Shi et al., arXiv 2017.
- [2] “Deep Learning Performance with P100 GPUs”, Rengan Xu and Nishanth Dandapanthu. Dell EMC HPC Innovation Lab. October 2016.
Difficulty and challenges in distirbuted deep learning
One of the major difficulties in distributed deep learning is that higher throughput does not always mean better training efficiency. For example, in data-parallel approach, the size of minibatch increases by adding more GPUs. However, when the minibatch size exceeds a certain threshold, larger batch size severely affects the model update and leads to lower validation accuracy. This is because, when training under the same number of epochs, the iteration number decreases in turn, so that the model cannot get matured enough. In addition, as the deviation in gradients gets smaller, it is well known that the model can easily fall into bad local minima (called sharp minima) so that the final model can have only poor generalization ability.
Without taking into account these circumstances, any benchmarking result only reporting good throughput performance makes no sense. No useful model can be trained just by pretending higher throughput due to too large batch size and/or reduced frequency of model synchronization. Therefore, though GPUs have sufficient memory capacity, we selected a relatively small batch size to achieve reasonable accuracy.
Future plan
After refinement based on feedback through internal trial in Preferred Networks starting February, we are going to publish ChainerMN as an open source software within a few months.
Appendix: details of performance evaluation
Experimental environment
- 32 node, 128 GPUs in total
- Node
- GPU: 4 * GeForce GTX TITAN X (Maxwell)
- CPU: 2 * Intel(R) Xeon(R) CPU E5-2623 v3 @ 3.00GHz
- Network: InfiniBand FDR 4X
Experimental setting
- Dataset: ImageNet-1k (1,281,158 images, already resized to 256x256 pixels before training)
- Model: ResNet-50 (input image size: 224x224)
- Training
- Batch size: 32 per GPU (32 x #GPU is the total batch size)
- Learning rate: multipy 0.1 after every 30 epochs
- Optimizer: Mometum SGD (momentum=0.9)
- Weight decay: 0.0001
- Training epoch: 100
Notes: these settings follow those of the original ResNet paper [3]. However, we did NOT use color nor scale augmentation in training, and 10-crop prediction nor fully-convolutional prediction in validation. Even under these conditions, ChainerMN achieved 71-72% in top-1 accuracy, which seem to be reasonable accuracy results, to the best of our knowledge.
- [3] “Deep Residual Learning for Image Recognition”, Kaiming He et al., CVPR 2016.
Appendix 2: details of framework settings
MXNet
- Our setup followed the official instruction.
- MXNet version: GitHub master at Jan. 2016 (0.9.1,
3a820bf7526d5c78f418a0ec2b01d4cd9977bbe7) - Additional build parameters:
USE_DIST_KVSTORE = 1,USE_BLAS=openblas - Python version: 2.7.6
- Out training code is based on the official ImageNet example.
- The example was already almost ready for us: ResNet and distributed training.
- The only modification is about data augmentation.
We tried dist_device_sync mode instead of dist_sync, but the result was not better. Therefore, we decided to use dist_sync as with the official example.
CNTK
- Our setup followed the official Dockerfile, including versions of dependencies.
- CNTK Version: GitHub master at Jan. 2016 (
d21dd4f47d4ed1bf6e5a04bad7e372364b8236b6) - MPI: OpenMP 1.10.3
- Python: Anaconda3 4.2.0
- Our training code is based on the official example for distributed training on CIFAR dataset.
CNTK prefers OpenMPI as stated here, so we used OpenMPI for CNTK.
TensorFlow
- Our setup followed the official instruction.
- TensorFlow version:
pip install https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-0.12.0-cp27-none-linux_x86_64.whl - Python: 2.7.6
- Our training code is based on the official ImageNet example.
- The example includes instructions for distributed training on ImageNet dataset.
- Parameter servers are different processes on the same nodes as those of workers.
- The number of parameter servers are n - 1, where n is the number of nodes.
As for the number of parameter servers, we tested different numbers of parameter servers to find the best one. It is a known issue that even numbers degrade the performance, so we used odd numbers. For the 128 GPU setting (where the number of nodes is 32), we tried 2^k - 1 for different k’s (i.e., 1, 3, 7, 15, …, 31, and 63), and found that 31 is the best. As it corresponds to n - 1, where n is the number of nodes, we used n - 1 for other experiments using different number of nodes.
About Chainer
Chainer is a Python-based, standalone open source framework for deep learning models. Chainer provides a flexible, intuitive, and high performance means of implementing a full range of deep learning models, including state-of-the-art models such as recurrent neural networks and variational autoencoders.
Recent Posts
- Chainer/CuPy v7 release and Future of Chainer
- Chainer/CuPy v7のリリースと今後の開発体制について
- Sunsetting Python 2 Support
- Released Chainer/CuPy v6.0.0
- ChainerX Beta Release
- Released Chainer/CuPy v5.0.0
- ChainerMN on AWS with CloudFormation
- Open source deep learning framework Chainer officially supported by Amazon Web Services
Categories
- General (12)
- Announcement (10)